两个程序员为 insert into select 着迷一晚,它到底有什么魔力
阅读数: 次



一、前言:
今天遇到一个事情,两个程序员对 insert into select 着迷一晚,这究竟是为神魔呢? 下面就简单说说原由;
当天,在 「MySql数据库」 中,程序员A使用 insert into select 对某张表中的一部分数据做备份,然后同时程序员B使用程序对这张表做数据插入操作,最后出现了程序员B的插入操作失败的情况,然后他们就研究了这个问题一晚上,最终找到了导致问题出现的原因。
下面就通过简单的模拟场景复现问题,然后并研究出现问题的原因,最后再找到避免问题出现的方法;
本文主线:
①、场景重现:模拟问题出现的场景
②、问题求解:研究问题出现的原因
③、最终结果:避免问题出现的方法
二、场景重现:模拟问题出现的场景
1、保证环境的一致:
出现问题时使用的mysql数据库的版本是 「5.7.16-log」 ;
不清楚自己使用的mysql版本的可以使用下面的语句进行查询,只要版本差不多就可以;
select version();
注意:创建一个新的数据库,保证这个库只有自己操作,主要是为了更加直观的重现问题及研究出现问题的原因,避免其它的干扰因素;
2、创建测试的表:
建表SQL如下:
日志表:
DROP TABLE IF EXISTS `t_log`;
CREATE TABLE `t_log` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`log` varchar(1024) DEFAULT NULL COMMENT '日志内容',
`createts` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
日志备份表:
DROP TABLE IF EXISTS `t_log_back`;
CREATE TABLE `t_log_back` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`log` varchar(1024) DEFAULT NULL COMMENT '日志内容',
`createts` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3、构造用于测试备份的数据:
在 t_log 表中新增 20 万 条数据,这些数据用于备份时使用; 使用存储过程在表中插入数据;
# 如果存储过程存在则删除
DROP PROCEDURE IF EXISTS proc_initData;
DELIMITER $
# 创建存储过程
CREATE PROCEDURE proc_initData()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<=200000 DO # 循环遍历插入的次数,循环遍历20万次
INSERT INTO t_log ( log ) VALUES ( CONCAT('测试日志log', i) ); #执行的插入sql语句
SET i = i+1;
END WHILE;
END $
# 调用存储过程
CALL proc_initData();
4、重现问题场景:
通过上面三步已经把出现问题时的基本环境复原,然后就使用SQL语句重现使两个程序员着迷的问题:
4.1、首先使用 navicat 可视化工具连接上创建的数据库;
4.2、然后开启 两个 命令列介面 :

4.3、然后先在第一个命令介面中手动开启一个事务,然后在另一个介面中也开启另一个事务:
start transaction ;
4.4、然后再在第一个命令介面中执行下面 insert into select 这个备份SQL语句:
注意:createts 创建时间筛选条件值需要改为自己表中对应的数据;
INSERT INTO t_log_back SELECT * FROM t_log WHERE CREATETS > STR_TO_DATE('2021-05-11 12:28:16','%Y-%m-%d %H:%i:%s') and CREATETS < STR_TO_DATE('2021-05-11 12:35:33','%Y-%m-%d %H:%i:%s');
4.5、然后接着在另一个命令介面中执行下面这个新增数据的SQL语句:
insert into t_log (log) values('insert into select test log');
此时会发现,insert 语句会被阻塞,直至超时插入失败;这是什么原因导致的呢?

如果对这方面有过了解的同学,可能知道这是由于你在第一个事务中使用 「insert into select」 进行备份时,没有commit 提交事务,导致 t_log 表一直处于 「被锁住」 的状态,所以其它事务再进行写操作时被阻塞;
确实是由于第一个事务没有提交导致其它事务的写操作被阻塞,这也跟两个程序员出现的问题情形一样,程序员A使用 insert into select 备份数据时,备份的数据量太大,导致事务长时间没有完成,最终导致程序员B的插入操作超时失败;
所以这也是网上很多资料都说尽量避免长事务的原因,因为会阻塞其它并发执行的写事务;
在这里大家是不是有两个疑问?
①、疑问一:insert into log 执行时导致 「锁表」 ,这个时候是直接使用的 「表锁」 实现的锁表吗?
注意: innodb 存储引擎支持行锁的,并且大家在网上查阅资料时应该都会查到 「“innodb的行锁是基于索引实现的:只有where条件存在索引时,InnoDB才使用行级锁,否则,InnoDB将直接使用表锁!”」 , 这句话真的对吗?;
②、疑问二:在不同的事务隔离级别下,表锁、行锁是否存在区别?
存在区别,主要是 行锁 在RC读提交、RR可重复读 隔离级别下存在区别,具体区别下文有说明;
三、问题求解:研究问题出现的原因
❝通过上面的场景重现,已经将问题复现了,并且知道了是由于存在长事务导致表被锁住了,进而导致了其它事务的写操作阻塞超时失败;
知道原因后,再研究下,到底是不是直接使用的 「表锁」 将表锁住的?
❞
通过上面提到的,网上查阅的资料,如果 「where条件中不存在索引」 ,那么就会直接使用表锁,那么按这么说的话在 insert into select 中使用 createts 创建时间字段进行查询数据时,由于 createts 没有索引,所以直接就是使用 表锁 喽;
但是大家需要知道的是,网上的资料千千万万,存在错误结论的也是不少的,所以说,我们不能当拿来主义,需要自己在实践操作下验证真伪,并且这样也会加深自己的理解;
1、下面我们就实践操作下,验证是否加的 表锁:
①、首先重新执行下 「重现问题场景」 的那五步;
②、然后再开启一个 查询界面,输入下面的SQL语句,查询当前事务中所持有的锁的信息:
select trx.trx_id, trx.trx_state, trx.trx_started, trx.trx_query, locks.lock_id, locks.lock_mode, locks.lock_type, locks.lock_table, locks.lock_index, trx.trx_rows_locked, trx.trx_isolation_level
from information_schema.INNODB_TRX trx, INFORMATION_SCHEMA.INNODB_LOCKS locks where trx.trx_id = locks.lock_trx_id
注意事项:
①、只有在SQL语句处于阻塞中时,执行下面的SQL语句才会得到锁的数据,所以执行完那五步后,需要立刻执行上面这个语句;
②、除了执行上面的SQL语句得到事务、锁信息外,还可以直接查询下innodb存储引擎的状态,在其中的事务模块得到需要的信息,语句如下:
show engine innodb status;
2、执行结果如下:

字段解析:
trx_id 事务id trx_state 事务状态 LOCK_WAIT:阻塞等待,RUNNING:运行中 trx_started 事务开始时间 trx_query 事务中执行的SQL语句 lock_id 事务所持有的锁的id lock_mode 锁的模式 X :排他锁(写锁),S:共享锁(读锁) lock_type 锁的类型 RECORD:行锁(记录锁),TABLE:表锁 lock_table 被加锁的表 lock_index 行锁使用到的索引,表锁时为 null trx_rows_locked 此事务锁定的 「大概数目或行数」 。该值可能包括物理上存在但对事务不可见的带有删除标记的行。 trx_isolation_level 此事务使用的隔离级别
3、执行结果解析:
3.1、trx_id为 235430:
通过执行结果得知,事务id为 235430 是执行 insert into select 的事务,由于此事务中SQL已执行完毕,所以在 trx_query 字段没有展示出具体SQL语句;
此事务持有的是行锁,通过全遍历 「聚簇索引」 将表中全部的行记录加 「行锁」 ,锁类型是共享读锁,trx_rows_locked 字段展示的值 「大概」 就是lock_table 被加锁的表中全部的数据量;
此事务使用的隔离级别是 「REPEATABLE READ 可重复读」 ;
3.2、trx_id为 235435:
事务id为 235435 是执行 insert 新增数据 的事务,此事务被阻塞,当进行插入数据时,也是通过遍历 「聚簇索引」 加行锁,锁类型是排它锁;
此事务使用的隔离级别是 「REPEATABLE READ 可重复读」 ;
3.3、结论 + 疑问?
①、结论:innodb的行锁是基于索引的,但是如果where条件中不存在索引的话,它会直接根据聚簇索引加行锁,每个表中都有主键,即使没有手动添加主键,mysql也会自动生成一个rowid(自增的)作为默认主键的;
所以不是直接加的 「表锁」 ,是加的行锁;
②、疑问:如果是对表中现有数据加行锁,那么 insert 新增数据时,是在最后面顺序插入数据,按理说不应该被阻塞的呀 ;
解答:需要知道当前事务使用的隔离级别是 「RR可重复读」 ,在RR隔离级别下是存在 「间隙锁」 的,在聚簇索引中除了加行锁之外,还会默认加上 间隙锁,通过 「行锁+间隙锁」 实现锁表;具体加锁如下图展示:
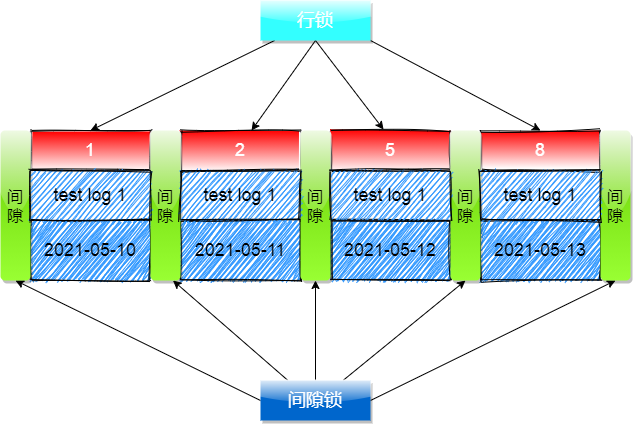
在mysql中 行锁+间隙锁 构成一种新的锁,叫做 「Next-Key Locks」,它除了可以在RR隔离级别下实现锁表,也用来避免 「幻读」 的发生;
注意:间隙锁是不存在于 「Read Uncommited(RU) 读未提交、Read Committed (RC) 读提交」 隔离级别下的;
如果间隙锁在RC读提交隔离级别下不存在,是不是在RC下就不会锁表了呢?并且也就不会导致文中说的问题啦?那下面我们来研究下;
四、最终结果:避免问题出现的方法
通过上面的介绍,可以得到两种可能避免问题出现的方法,但是需要去实践下:
①、RR隔离级别下,在 createts 创建时间字段上创建二级索引;
②、将当前数据库的事务隔离级别设置为 RC 读提交;
1、避免问题出现方法一:创建索引
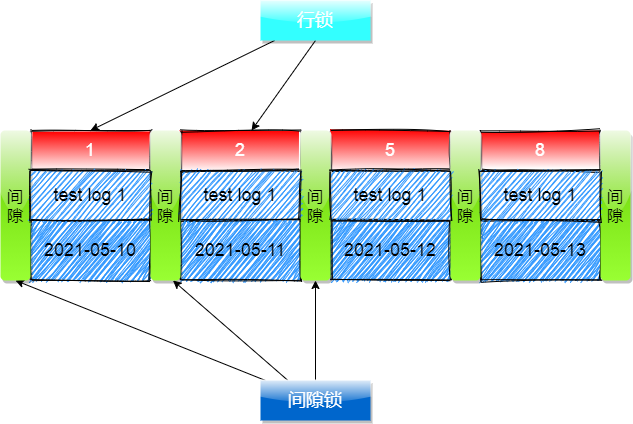
RR隔离级别下,在 createts 字段上创建索引,重新执行下 「重现问题场景」 的那五步,发现insert新增数据时事务没有被阻塞;
因为innodb的行锁是基于索引的,如果where条件字段存在索引的话,会先根据二级索引筛选出主键值,然后再回表到聚簇索引中对筛选出的主键值对应的记录加行锁,以及加行锁的记录之间默认加上间隙锁;
加锁展示如下:通过下图展示,发现最后面的间隙没有上锁,所以insert操作就不会被阻塞了;
2、避免问题出现方法二:设置隔离级别为RC
除了对where条件字段创建索引外,还可以直接将当前数据库事务的隔离级别设置为 RC 读提交;
设置事务的RC隔离级别的SQL语句如下:
SET global TRANSACTION ISOLATION LEVEL Read committed;
设置完事务的RC隔离级别后,重新执行下 「重现问题场景」 的那五步,发现insert新增数据时事务没有被阻塞,说明此方式也是可行的;
并且通过查阅官网资料得知:使用 RC 隔离级别时,MySQL评估WHERE条件后,将会释放不匹配行的记录锁;具体如下所示:
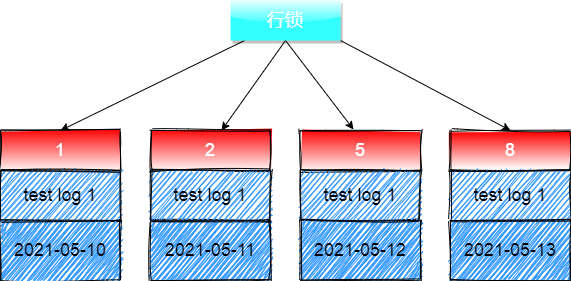
在RC隔离级别下执行下面这个SQL语句:
INSERT INTO t_log_back SELECT * FROM t_log WHERE CREATETS > STR_TO_DATE('2021-05-11','%Y-%m-%d') and CREATETS < STR_TO_DATE('2021-05-13','%Y-%m-%d');
先扫描 聚簇索引 加行锁:
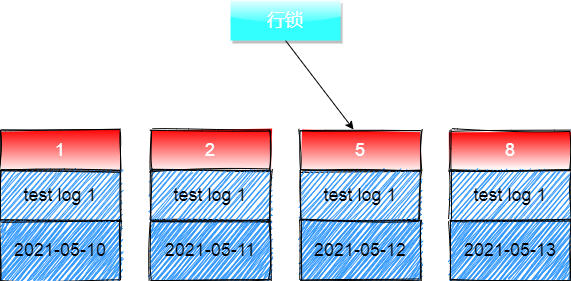
然后MySql进行评估优化后,将不满足where条件的行记录锁释放掉,最后如下所示:
2.1、知识面扩展:
其实目前大多数的互联网项目中mysql事务隔离级别都是使用的RC读提交,一是因为在大多数场景下使用RC都是可以的,二是像Oracle数据库默认的事务隔离级别也是 RC 读提交,大家在使用Oracle数据库时也是直接使用,没有去修改过其隔离级别;
疑问?那mysql为什么将默认的事务隔离级别设置为 RR 呢?
主要是因为mysql一个遗留的历史问题导致,因为在RC隔离级别下,使用 「statement 格式的 binlog」 进行主从同步时,会导致主从数据不一致;但是后面binlog提供了 row 等格式,这时在RC下就可以避免数据不一致问题了;
所以如果将事务的隔离级别设置为 RC 读提交的话,并且当前也需要使用binlog 进行主从同步的话,需要将binlog日志的格式改为 row;
查看当前数据库的binlog的格式的SQL语句:
show variables like 'binlog_format'
修改当前数据库的binlog的格式的SQL语句:
set globle binlog_format='ROW'
五、总结:
至此,本文已经将 insert into select 具有的魔力聊完了;
读完本文后,希望大家在明白了 insert into select 具体的魔力时,也能明白本文中传递的一个重要内容,不要拿来主义,多实践;
还有就是大家在阅读本文时,也要跟着实操一遍,遇到与本文中描述的不一样的地方时,也要保持着怀疑态度,心想,这块是不是博主写错啦;
大家在查阅资料时,尽可能去官网查阅相关资料,因为官网的资料全且清晰正确;
六、参考资料:
①、INFORMATION_SCHEMA INNODB_TRX表
③、INFORMATION_SCHEMA INNODB_LOCKS表
❤ 点赞 + 评论 + 转发 哟
如果本文对您有帮助的话,请挥动下您爱发财的小手点下赞呀,您的支持就是我不断创作的动力,谢谢啦!
您可以微信搜索 「【木子雷】」 公众号,大量Java学习干货文章,您可以来瞧一瞧哟!

- 文章连结: https://leishen6.github.io/2021/05/15/insert_into_select/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!
